
Pendekatan Regression Language Model (RLM) terbaru dari Google AI memungkinkan Large Language Models (LLM) untuk memprediksi kinerja sistem industri secara langsung dari data teks mentah, tanpa bergantung pada rekayasa fitur yang rumit atau format tabular yang kaku.
Inovasi ini menjanjikan revolusi dalam cara kita memahami dan mengoptimalkan sistem kompleks seperti klaster komputasi dan lini produksi.
Tantangan dalam memprediksi kinerja sistem industri skala besar, seperti klaster komputasi Borg milik Google, secara tradisional membutuhkan rekayasa fitur khusus domain dan representasi data tabular yang ekstensif. Log, file konfigurasi, kombinasi perangkat keras yang bervariasi, dan data pekerjaan bertingkat tidak dapat dengan mudah diratakan atau dinormalisasi untuk model regresi klasik. Akibatnya, alur kerja optimasi dan simulasi sering kali menjadi rapuh, mahal, dan lambat, terutama ketika jenis beban kerja atau perangkat keras baru diperkenalkan. Dengan RLM, Google mencoba memecahkan masalah ini dengan pendekatan yang lebih fleksibel dan mudah beradaptasi.
Inti dari RLM adalah mengubah regresi menjadi tugas pembuatan teks. Semua data keadaan sistem (konfigurasi, log, profil beban kerja, deskripsi perangkat keras) diserialisasikan ke dalam format teks terstruktur seperti YAML atau JSON dan digunakan sebagai prompt input (xxx). Model regresi kemudian mengeluarkan target numerik (yyy)—seperti metrik efisiensi (Millions of Instructions Per Second per Google Compute Unit, MIPS per GCU)—sebagai respons string teks.
Pendekatan ini menghilangkan kebutuhan akan feature engineering, normalisasi, dan skema pengkodean yang kaku. Karena semua keadaan sistem dapat direpresentasikan sebagai string, RLM secara alami mendukung fitur heterogen, bertingkat, atau berkembang secara dinamis. Fleksibilitas ini sangat penting dalam lingkungan industri yang kompleks dan terus berubah.
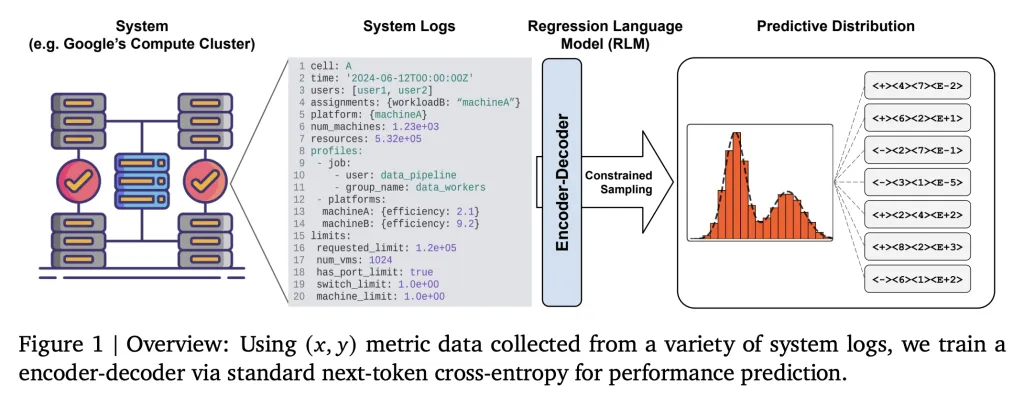
Secara teknis, RLM menggunakan LLM encoder-decoder yang relatif kecil (60 juta parameter) yang dilatih melalui cross-entropy loss token berikutnya pada representasi string dari xxx dan yyy. Model ini tidak dilatih sebelumnya pada pemodelan bahasa umum—pelatihan dapat dimulai dari inisialisasi acak, berfokus langsung pada menghubungkan keadaan sistem dengan hasil numerik. Hasil dinumerisasi secara efisien (misalnya, pengkodean mantissa-sign-exponent P10) untuk merepresentasikan nilai floating-point dalam kosakata model. RLM yang telah dilatih sebelumnya dapat dengan cepat disesuaikan dengan tugas baru hanya dengan 500 contoh, beradaptasi dengan konfigurasi klaster atau bulan baru dalam hitungan jam, bukan minggu. Model ini juga dapat memproses teks masukan yang sangat panjang (ribuan token), memastikan bahwa keadaan kompleks diamati sepenuhnya.
Dalam pengujian pada klaster Borg, RLM mencapai korelasi peringkat Spearman hingga 0,99 (rata-rata 0,9) antara MIPS per GCU yang diprediksi dan yang sebenarnya, dengan mean squared error 100x lebih rendah daripada baseline tabular. Model ini secara alami menguantifikasi ketidakpastian dengan mengambil sampel beberapa keluaran untuk setiap masukan, mendukung simulasi sistem probabilistik dan alur kerja optimasi Bayesian. Tidak seperti sebagian besar black-box regressor, RLM menangkap baik ketidakpastian aleatoric (inheren) maupun epistemic (tidak diketahui karena keterbatasan observasi). Kemampuan pemodelan densitas RLM menunjukkan penggunaannya dalam membangun digital twins universal untuk sistem skala besar, mempercepat optimasi infrastruktur, dan umpan balik waktu nyata.
Jika dibandingkan dengan regresi tradisional yang membutuhkan format data flat dan rekayasa fitur manual, RLM menawarkan adaptasi yang tinggi dan kinerja yang mendekati sempurna tanpa memerlukan rekayasa fitur. Selain itu, RLM menyediakan spektrum ketidakpastian yang lengkap, sementara regresi tabular hanya memberikan ketidakpastian minimal.
Aplikasi potensial RLM sangat luas, mulai dari prediksi dan optimasi kinerja untuk infrastruktur cloud dan klaster komputasi yang besar dan dinamis, hingga simulator universal untuk prediksi hasil di berbagai pipeline industri di bidang manufaktur dan IoT. RLM juga dapat digunakan dalam eksperimen ilmiah end-to-end di mana keadaan masukan kompleks, dijelaskan secara tekstual, dan beragam secara numerik.
Dengan memperlakukan regresi sebagai pemodelan bahasa, RLM menghilangkan hambatan lama dalam simulasi sistem, memungkinkan adaptasi cepat ke lingkungan baru, dan mendukung prediksi sadar ketidakpastian yang kuat. Semua ini sangat penting untuk AI industri generasi berikutnya.
Sumber: marktechpost